Kafka 工作机制
Kafka 是 Apache 的子项目,是一个高性能跨语言的分布式发布/订阅消息队列系统(没有严格实现 JMS 规范的点对点模型,但可以实现其效果),在企业开发中有广泛的应用。高性能是其最大优势,劣势是消息的可靠性(丢失或重复),这个劣势是为了换取高性能,开发者可以以稍降低性能,来换取消息的可靠性。
作者:王克锋
出处:https://kefeng.wang/2017/11/15/kafka-mechanism/
版权:自由转载-非商用-非衍生-保持署名,转载请标明作者和出处。
1 Kafka 的历史
官网: http://kafka.apache.org/
文档: https://kafka.apache.org/documentation/
Kafka 最初由领英(LinkedIn)开发,于2011年初开源,并于2012年10月23日由Apache Incubator孵化出站。
2014年11月,几个曾在领英为Kafka工作的工程师,创建了名为Confluent的新公司,[5],并着眼于Kafka。
Kafka 的命名来自于作家Franz Kafka(弗朗茨·卡夫卡),意为“一个用于优化写作的系统”。
2 Kafka 相关术语
- 主题的复制因子(replication factor): 表示该主题的每个消息都复制至N个服务器上,当多达N-1个服务器故障时,该消息依旧可以访问;
- 主题的分区(partition): 一个主题可以拆分存储在多个分区(各分区可以在不同的服务器上);
每个分区是一个有序不变的消息序列,每个消息都分配唯一性ID(称作 offset),新消息按顺序追加到分区尾部(磁盘的顺序读写比随机读写高效的多);
分区的作用:突破单个 broker 磁盘容量限制、多分区并行以提高效率;
消息所在分区的选择:生产者(开发者)选择算法,可以是轮询负载均衡,也可以是根据权重或算法(设置 Producer 的 paritition.class 参数,该class必须实现kafka.producer.Partitioner接口,按消息中的 KEY 计算)选择,理想情况是消息均匀地分布到不同分区中;
分区日志文件放在日志目录(参数log.dirs)下,文件名形式为toppicName-partitionId(总长度限制为 255 字符)。 - 各服务器在分区上的分工: 每个分区的多个副本中,都有一个副本作为 Leader(处理分区的所有读写请求);有多个 Followers(从 Leader 复制消息,以实现容错);一个服务器可以同时作为多个分区的 Leader 或 Followers;生产者将数据直接发送给作为分区 Leader 的 Broker,而无需任何中间路由层。
- 有序消费的保证: 每个主题的每个消费者都记录有一个消费偏移(消费者可以修改该偏移),表示接下来的读取位置,读取后该偏移会身后偏移;
- 消息有效期(可配置)机制: 有效期内的消息保留(未消费的消息可以被消费),一旦过期就丢弃(无论是否已被消费),消息存储的信息包括 key/value/timestamp
- 消息持久化:写入磁盘并进行复制以实现容错,允许生产者等待确认完整写入。可以将Kafka视为专用于高性能,低延迟提交日志存储,复制和传播的专用分布式文件系统。
3 Kafka 的架构
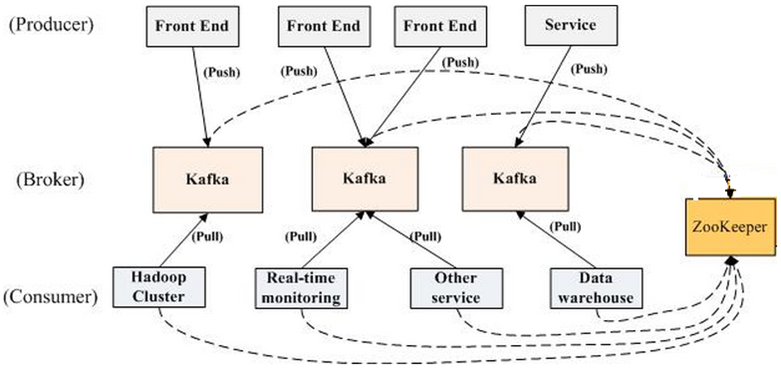
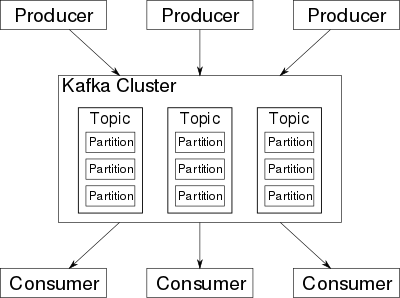
一个典型的 Kafka Cluster(集群)中包含:
- 若干 Producer(消息生产者): 将 record(记录,相当于消息) Publish(发布,Push方式) 至 Broker,Producer 可以是前端页面、服务器日志、系统CPU、内存等;
- 若干 Broker(用来存储消息的主服务器): 支持水平扩展(数量越多,集群吞吐越好),消息的存储是按 Topic(主题,消息的分类)+Partition(主题分区) 划分;
特定的 Topic/Partition 内各消息的 offset(偏移) 与消息的时间戳一起保存,当消息存储至过期时间(服务器中可配置)后,将自动删除以释放空间(无论是否已被消费); - 若干 Consumer(消息的消费者): Subscribe(订阅) Topic 并从某个 Partition 中拉取消息(Pull);
每个主题针对每个消费者都保存了其当前消费位置(offset,该值可人为移动),下次消费时会从该位置拉取,然后 offset 向后移动;
每个 Consumer 属于一个特定的 Consumer Group(可明确指定,也可不指定默认为 group); - 一个 Zookeeper 集群: Broker 端不维护数据的消费状态,而且委托给 ZooKeeper,提升了性能;
Kafka 的 Producer/Consumer/Broker(Topic+Partition) 通过 ZooKeeper 存储状态信息并协调(在变化时通知相关方);
还用于选举 Partition Leader 并存储相关信息,Consumer 注册 ZooKeeper的Watch以跟踪 Leader 变化。
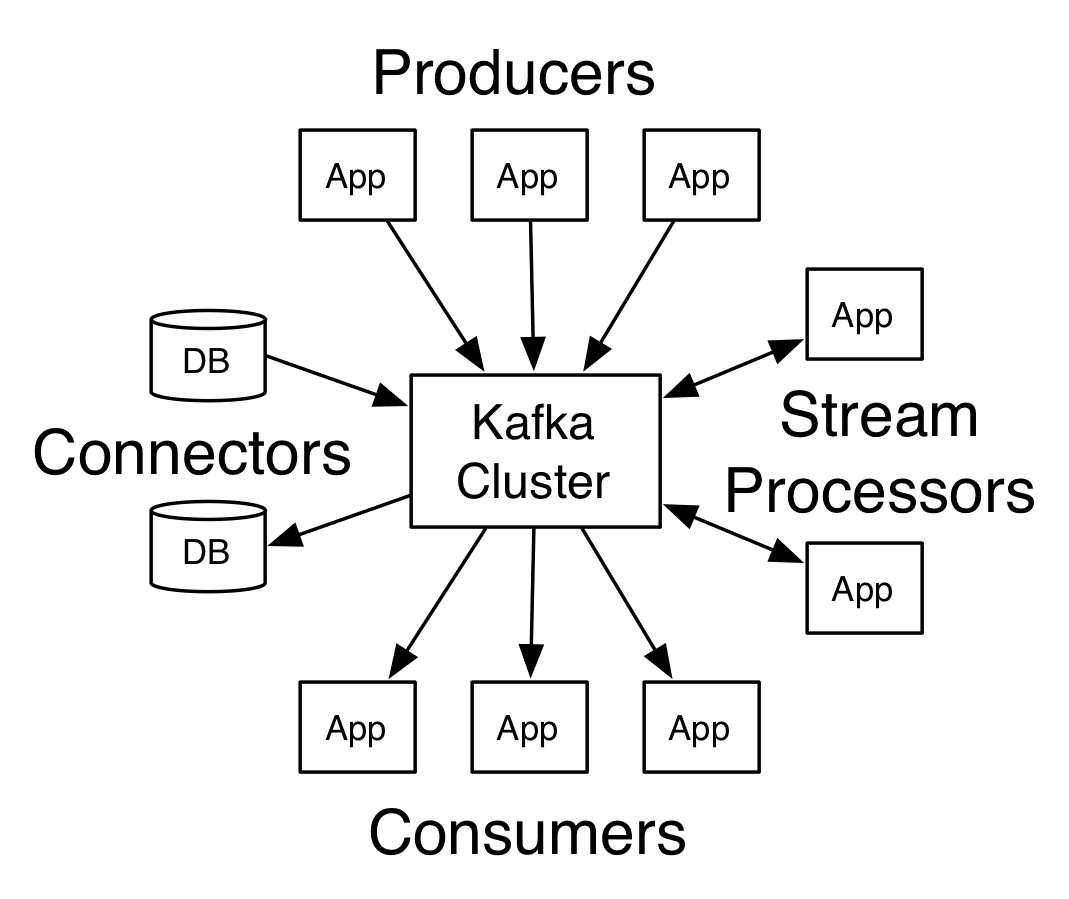
此外,Kafka 还可以通过 Connect 连接到外部系统(比如对接DB,用于数据输入/输出),并提供了流式处理库 Streams(比如对接 Storm/HBase/Spark,将输入流转换为输出流)。
4 Kafka 的消息模型
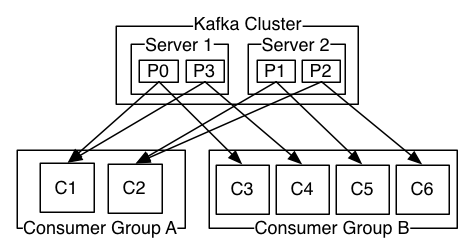
传统消息有两种模型:点对点(queue, 每个消息只被一个消费者消费)、发布/订阅(topic,消息被群发给订阅者)。
Kafka 提供了单一的消费者模型:消费者组(Consumer Group),消费者都有消费者组(不指定时默认为 group),Topic 上的每个消息只会被订阅该主题的各消息组中的一个消费者收取:
- 点对点模型的效果:所有的消费者都在一个组中,各消费者瓜分消息;只是与传统消息不同,消息被消费后不会被删除,过期后才会删除;
- 发布/订阅模型的效果:所有的消费者在不同的消费者组中,同一个消息可以被不同组的各个消费者收取,同一分组的各消费者起到了扩展性能的效果。
Kafka 在消息的消费方式上是有区别的:
- 在 JMS 中,Broker 主动将消息 Push(推送)给 Consumer;
- 而 Kafka 中,消息是由 Consumer 主动从 Broker 拉取(Pull),即 Consumer 和 Broker建立连接后,根据自己的消费能力(这与 JMS 相比是个优势),主动去pull(fetch)消息。
5 ZooKeeper 中保存的信息
Zookeeper 中保存的 Kafka 数据结构:Kafka data structures in Zookeeper
- broker Node:
/brokers/ids/[N](非持久) 由 broker 启动后注册,停止后删除; - Broker Topic/Partitions:
/broker/topics/[topic]/partitions/[N](非持久) - Consumer/ConsumerId/ConsumerGroup/ConsumerOffset:
/consumers(非持久) - Partition Owner:
Zookeeper 在 Kafka 中的协调作用:
- Producer 通过 Zookeeper 发现 Broker 列表,和 Topic 下每个 Partition Leader 建立连接并推送消息;
- Broker 向 Zookeeper 注册 Broker 信息,监测 Partition Leader 的存活性;
- Consumer 通过 Zookeeper 发现 Broker 列表,并向 Zookeeper 注册 Consumer 信息(包括 Consumer 的 Partition 列表),并和 Partition Leader 建立连接以拉取消息。
6 Kafka 的监控
监控对象包括 Broker/Producer/Consumer/ZooKeeper 等;
开源的监控平台有领英的Burrow,付费的有Datadog,还可以借助 JConsole 收集信息。
7 Kafka 的应用
Kafka 集群很好地支持 Unix/Linux/Solaris,但 Windows 下欠佳(不要作为生产环境)。
Kafka 的用户中包括 LinkedIn, Yahoo, Twitter, Uber, PayPal, Airbnb, Tumblr, Mozilla, Oracle, IBM, ebay, Yelp, Netflix, 高盛, 纽约时报, 思科系统, 沃尔玛等(更多清单见 这里)。
被用于日志收集,实时分析(Storm),离线分析(Hadoop),消息管道等。应用场景包括:
- 消息: 将数据的生成和处理分离,缓冲未处理的消息;
- 网站活动: 实时处理,实时监控,加载到Hadoop或离线数据仓库系统以进行离线处理和报告;
- 日志聚合: 从服务器收集物理日志文件;
- 流处理: 原始输入数据从Kafka主题中消耗,然后聚合,丰富或以其他方式转化为新的主题,以供进一步消费或后续处理。
8 Kafka 生态系统
官方文档: https://docs.confluent.io/2.0.0/connect/index.html
连接器(Connectors): https://www.confluent.io/product/connectors/
- JDBC/MySQL/Oracle/DB2/PostgreSQL, Redis
- ActiveMQ/RabbitMQ, ElasticSearch, Jenkins
- HDFS(Hadoop/Hive/Storm/Flume)
- Github/Twitter, FTP
9 Kafka 依赖环境
安装 JRE 环境,版本要求 1.7+;
Kafka 使用 ZooKeeper,安装详见文章 ZooKeeper 原理与集群部署
